在Kilo Code中使用Ollama
Kilo Code 支持通过 Ollama 在本地运行模型。这提供了隐私保护、离线访问能力,并可能降低成本,但需要更多设置且依赖高性能计算机。
官方网站: https://ollama.com/
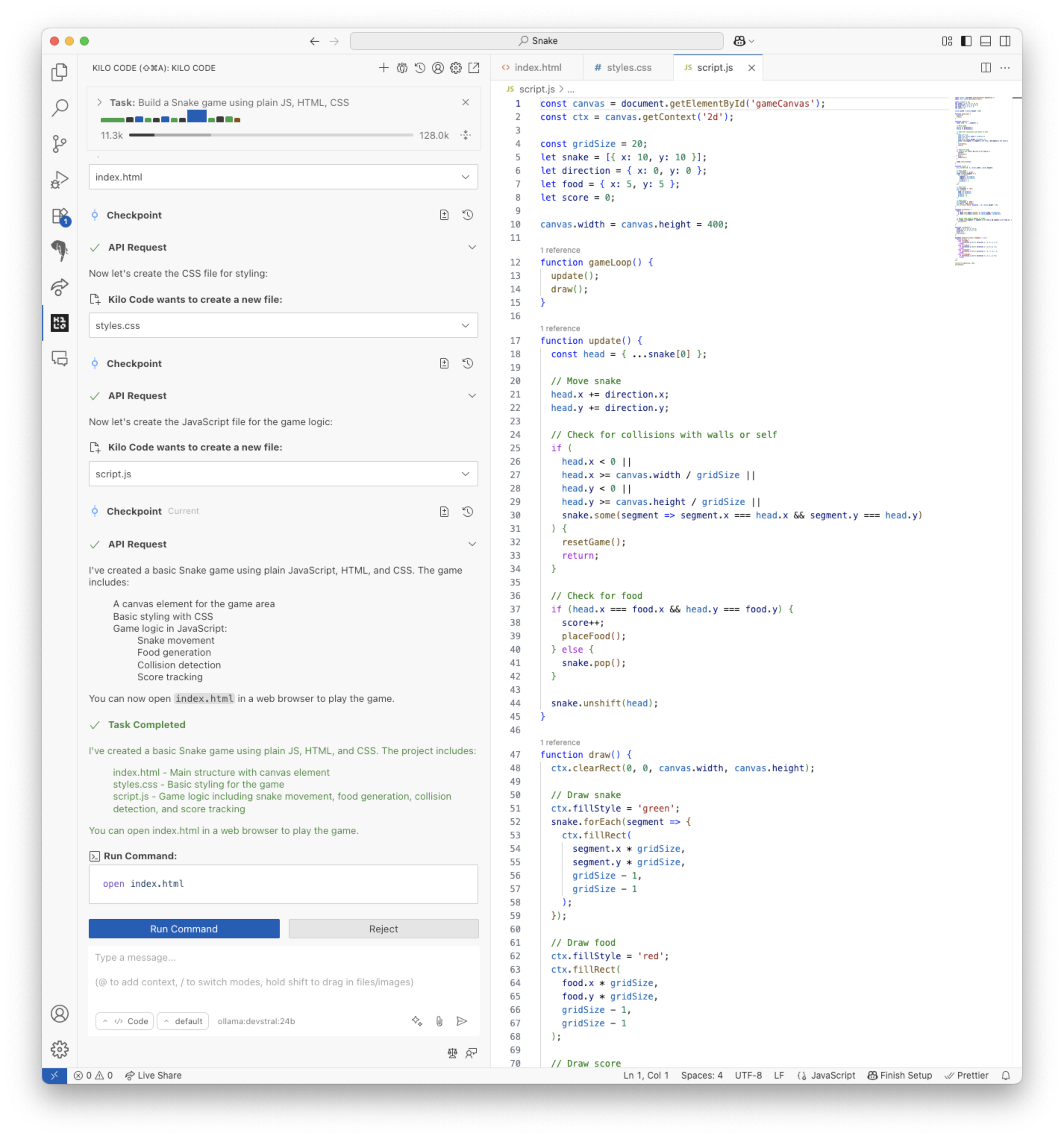
使用 devstral 编写贪吃蛇游戏
管理期望
本地 LLM 比高级云托管 LLM(如 Claude 和 Gemini)小得多,结果也会逊色得多。 它们更容易陷入循环,无法正确使用工具或在代码中产生语法错误。 需要更多的试错才能找到正确的提示。 本地 LLM 通常速度也不是很快。 使用简单的提示、保持对话简短和禁用 MCP 工具可以提高速度。
硬件要求
您将需要大量的 RAM(32GB 或更多)和强大的 CPU(例如 Ryzen 9000 系列)才能运行下面列出的模型。 GPU 可以更快地运行 LLM,但需要大量的 VRAM(24GB 或更多),这在消费级 GPU 上并不常见。 较小的模型可以在更普通的 GPU 上运行,但效果不佳。 具有足够统一内存的 MacBook 可以使用 GPU 加速,但在我们的测试中,其性能不如高端桌面 CPU。
选择模型
Ollama 支持许多不同的模型。 您可以在 Ollama 网站上找到可用模型列表。 选择适合您的用例、在您的硬件配置上运行并达到所需速度的模型需要一些试错。 以下规则和启发式方法可用于查找模型:
- 必须至少有 32k 的上下文窗口(这是 Kilo Code 的要求)。
- 列出为支持工具。
- 参数数量在 7b 到 24b 范围内。
- 优先选择流行模型。
- 优先选择较新的模型。
Kilo Code 推荐
我们使用以下提示测试了一些模型:
创建一个简单的网页,其中包含一个按钮,单击时会向用户问好。
如果模型在几次尝试内产生了一个可用的结果,则认为它通过。我们发现可以正常工作的模型是:
| 模型名称 | 完成时间 |
|---|---|
| qwen2.5-coder:7b | 1x(基线) |
| devstral:24b | 2x |
| gemma3:12b | 4x |
| qwen3-8b | 12x |
我们的建议是,如果您的硬件能够处理,请使用 devstral:24b,因为它比 qwen2.5-coder:7b 犯的错误更少。 qwen2.5-coder:7b 值得考虑,因为它速度快,如果您能忍受它的错误。 该表还显示速度难以预测,因为专用 devstral:24b 在这里优于较小的通用模型 gemma3:12b 和 qwen3-8b。 gemma3:12b 的结果引人注目,因为它能够正确使用工具(至少有时),而 Ollama 网站上并未将其列为适合工具使用的模型。
devstral:24b 产生的结果如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>问候用户按钮</title>
<style>
body {
font-family: Arial, sans-serif;
display: flex;
justify-content: center;
align-items: center;
height: 100vh;
margin: 0;
}
button {
padding: 10px 20px;
font-size: 16px;
cursor: pointer;
}
</style>
</head>
<body>
<button onclick="greetUser()">问候我!</button>
<script>
function greetUser() {
alert('你好!欢迎来到我们的网站。');
}
</script>
</body>
</html>
以下模型看起来是合理的选择,但发现与 Kilo Code 的默认配置不兼容:
| 模型名称 | 失败原因 |
|---|---|
| deepseek-r1:7b | 无法正确使用工具 |
| deepseek-r1:8b | 陷入推理循环 |
设置 Ollama
-
下载并安装 Ollama: 从 Ollama 网站下载适用于您操作系统的 Ollama 安装程序。按照安装说明进行操作,并设置
OLLAMA_CONTEXT_LENGTH环境变量以防止 Ollama 截断提示。确保 Ollama 正在运行:OLLAMA_CONTEXT_LENGTH=131072 ollama serve -
下载模型: 下载模型后,您可以离线使用 Kilo Code 和该模型。要下载模型,请打开终端并运行:
ollama pull <model_name>例如:
ollama pull devstral:24b -
配置 Kilo Code:
- 打开 Kilo Code 侧边栏(
 图标)。
图标)。 - 单击设置齿轮图标()。
- 选择“ollama”作为 API 提供商。
- 输入模型名称。
- (可选)如果您在不同的机器上运行 Ollama,则可以配置基本 URL。默认值为
http://localhost:11434。
- 打开 Kilo Code 侧边栏(
进一步阅读
有关安装、配置和使用 Ollama 的更多信息,请参阅 Ollama 文档。