Codebase Indexing
Codebase Indexing enables semantic code search across your entire project using AI embeddings. Instead of searching for exact text matches, it understands the meaning of your queries, helping Kilo Code find relevant code even when you don't know specific function names or file locations.
What It Does
When enabled, the indexing system:
- Parses your code using Tree-sitter to identify semantic blocks (functions, classes, methods)
- Creates embeddings of each code block using AI models
- Stores vectors in a Qdrant database for fast similarity search
- Provides the
codebase_searchtool to Kilo Code for intelligent code discovery
This enables natural language queries like "user authentication logic" or "database connection handling" to find relevant code across your entire project.
Key Benefits
- Semantic Search: Find code by meaning, not just keywords
- Enhanced AI Understanding: Kilo Code can better comprehend and work with your codebase
- Cross-Project Discovery: Search across all files, not just what's open
- Pattern Recognition: Locate similar implementations and code patterns
Setup Requirements
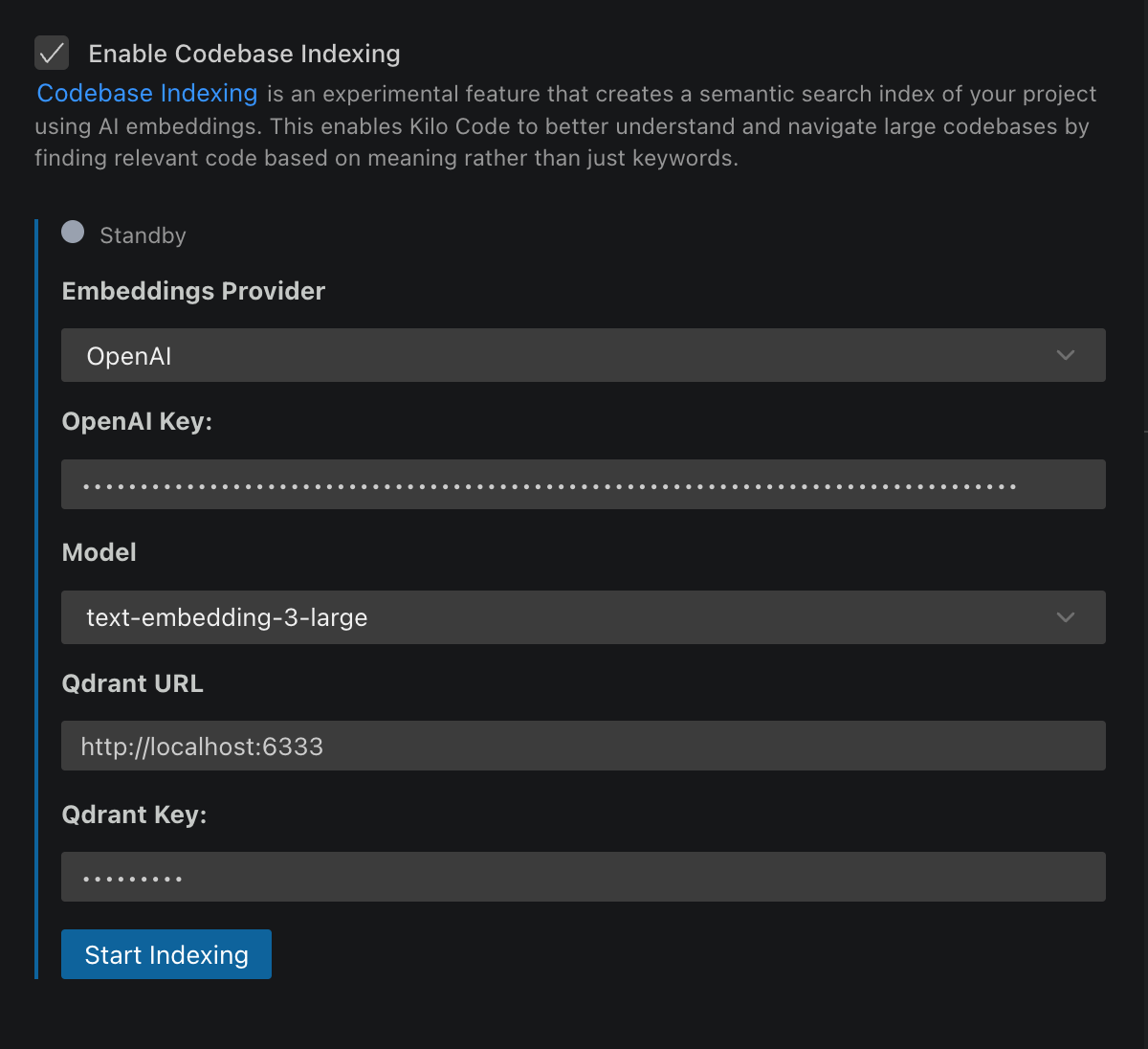
Embedding Provider
Choose one of these options for generating embeddings:
OpenAI (Recommended)
- Requires OpenAI API key
- Supports all OpenAI embedding models
- Default:
text-embedding-3-small - Processes up to 100,000 tokens per batch
Gemini
- Requires Google AI API key
- Supports Gemini embedding models including
gemini-embedding-001 - Cost-effective alternative to OpenAI
- High-quality embeddings for code understanding
Ollama (Local)
- Requires local Ollama installation
- No API costs or internet dependency
- Supports any Ollama-compatible embedding model
- Requires Ollama base URL configuration
Vector Database
Qdrant is required for storing and searching embeddings:
- Local:
http://localhost:6333(recommended for testing) - Cloud: Qdrant Cloud or self-hosted instance
- Authentication: Optional API key for secured deployments
Setting Up Qdrant
Quick Local Setup
Using Docker:
docker run -p 6333:6333 qdrant/qdrant
Using Docker Compose:
version: '3.8'
services:
qdrant:
image: qdrant/qdrant
ports:
- '6333:6333'
volumes:
- qdrant_storage:/qdrant/storage
volumes:
qdrant_storage:
Production Deployment
For team or production use:
- Qdrant Cloud - Managed service
- Self-hosted on AWS, GCP, or Azure
- Local server with network access for team sharing
Configuration
- Open Kilo Code settings ( icon)
- Navigate to Codebase Indexing section
- Enable "Enable Codebase Indexing" using the toggle switch
- Configure your embedding provider:
- OpenAI: Enter API key and select model
- Gemini: Enter Google AI API key and select embedding model
- Ollama: Enter base URL and select model
- Set Qdrant URL and optional API key
- Configure Max Search Results (default: 20, range: 1-100)
- Click Save to start initial indexing
Enable/Disable Toggle
The codebase indexing feature includes a convenient toggle switch that allows you to:
- Enable: Start indexing your codebase and make the search tool available
- Disable: Stop indexing, pause file watching, and disable the search functionality
- Preserve Settings: Your configuration remains saved when toggling off
This toggle is useful for temporarily disabling indexing during intensive development work or when working with sensitive codebases.
Understanding Index Status
The interface shows real-time status with color indicators:
- Standby (Gray): Not running, awaiting configuration
- Indexing (Yellow): Currently processing files
- Indexed (Green): Up-to-date and ready for searches
- Error (Red): Failed state requiring attention
How Files Are Processed
Smart Code Parsing
- Tree-sitter Integration: Uses AST parsing to identify semantic code blocks
- Language Support: All languages supported by Tree-sitter
- Markdown Support: Full support for markdown files and documentation
- Fallback: Line-based chunking for unsupported file types
- Block Sizing:
- Minimum: 100 characters
- Maximum: 1,000 characters
- Splits large functions intelligently
Automatic File Filtering
The indexer automatically excludes:
- Binary files and images
- Large files (>1MB)
- Git repositories (
.gitfolders) - Dependencies (
node_modules,vendor, etc.) - Files matching
.gitignoreand.kilocodepatterns
Incremental Updates
- File Watching: Monitors workspace for changes
- Smart Updates: Only reprocesses modified files
- Hash-based Caching: Avoids reprocessing unchanged content
- Branch Switching: Automatically handles Git branch changes
Best Practices
Model Selection
For OpenAI:
text-embedding-3-small: Best balance of performance and costtext-embedding-3-large: Higher accuracy, 5x more expensivetext-embedding-ada-002: Legacy model, lower cost
For Ollama:
mxbai-embed-large: The largest and highest-quality embedding model.nomic-embed-text: Best balance of performance and embedding quality.all-minilm: Compact model with lower quality but faster performance.
Security Considerations
- API Keys: Stored securely in VS Code's encrypted storage
- Code Privacy: Only small code snippets sent for embedding (not full files)
- Local Processing: All parsing happens locally
- Qdrant Security: Use authentication for production deployments
Current Limitations
- File Size: 1MB maximum per file
- Single Workspace: One workspace at a time
- Dependencies: Requires external services (embedding provider + Qdrant)
- Language Coverage: Limited to Tree-sitter supported languages for optimal parsing
Using the Search Feature
Once indexed, Kilo Code can use the codebase_search tool to find relevant code:
Example Queries:
- "How is user authentication handled?"
- "Database connection setup"
- "Error handling patterns"
- "API endpoint definitions"
The tool provides Kilo Code with:
- Relevant code snippets (up to your configured max results limit)
- File paths and line numbers
- Similarity scores
- Contextual information
Search Results Configuration
You can control the number of search results returned by adjusting the Max Search Results setting:
- Default: 20 results
- Range: 1-100 results
- Performance: Lower values improve response speed
- Comprehensiveness: Higher values provide more context but may slow responses
Privacy & Security
- Code stays local: Only small code snippets sent for embedding
- Embeddings are numeric: Not human-readable representations
- Secure storage: API keys encrypted in VS Code storage
- Local option: Use Ollama for completely local processing
- Access control: Respects existing file permissions
Future Enhancements
Planned improvements:
- Additional embedding providers
- Multi-workspace indexing
- Enhanced filtering and configuration options
- Team sharing capabilities
- Integration with VS Code's native search